Авторский материал
Парадокс наблюдаемости: почему традиционный мониторинг бесполезен для автономных ИИ-агентов
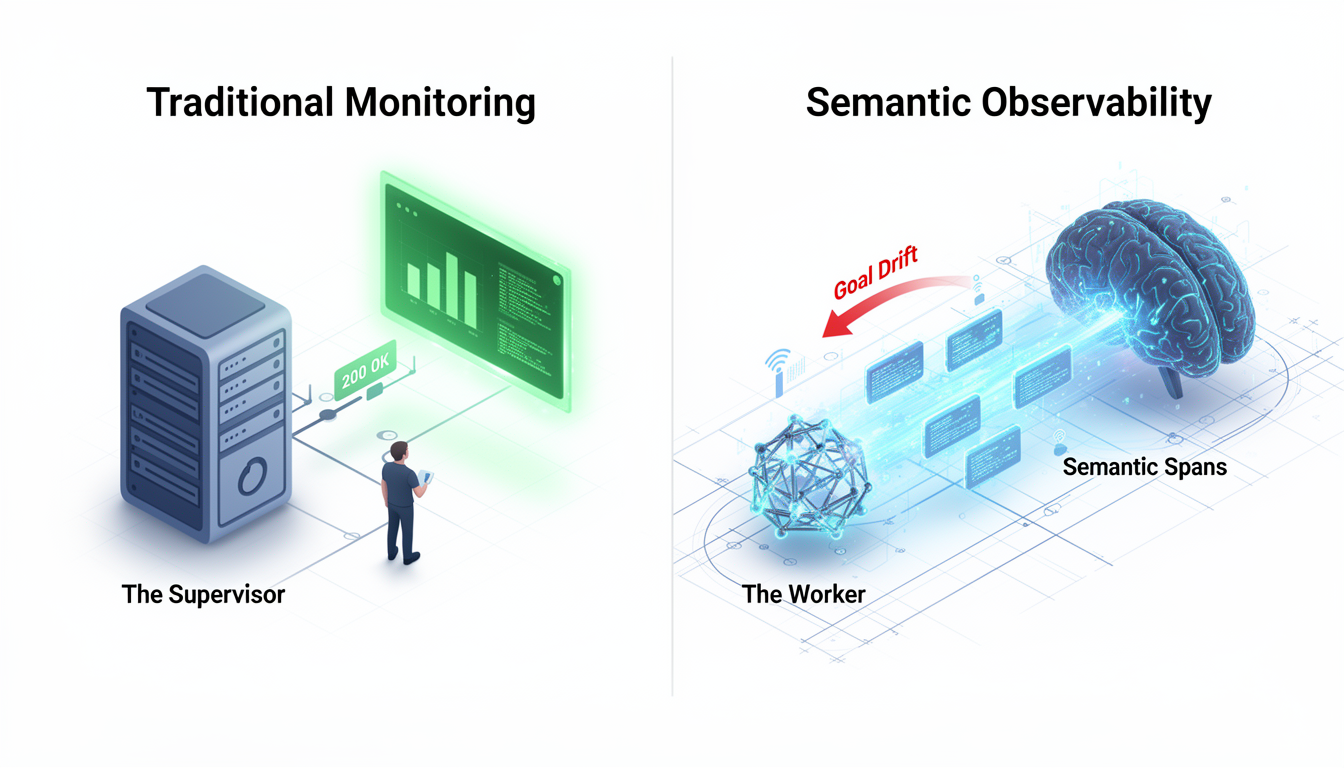
Инфраструктурные дашборды могут «светиться зеленым», пока бизнес-логика агента находится в состоянии коллапса. Разбираемся, в чем суть семантического разрыва.

Автор и проверка


В классической архитектуре ПО наблюдаемость (Observability) строится на трех фундаментальных столпах: логи, метрики и распределенные трейсы. Эта модель была создана для детерминированных систем. Если микросервис вернул HTTP 500, задержка запроса превысила 500мс или загрузка CPU достигла 90% — мониторинг сигнализирует об ошибке. Всё прозрачно, измеримо и поддается автоматизации через алерты.
В агентных системах эта модель сталкивается с «семантическим разрывом». Агент может вернуть HTTP 200, отработать в рамках заданного тайм-аута и при этом абсолютно провалить задачу, полностью уклонившись от цели в процессе итераций. Мы попадаем в ловушку, когда инфраструктурные дашборды светятся зеленым, в то время как бизнес-логика находится в состоянии глубокого коллапса.
1. Смерть UI-центричного мониторинга и переход к Machine-Readable Telemetry
Последнее десятилетие вендоры observability (Datadog, New Relic, Grafana) вели «войну интерфейсов». Главной ценностью стали красивые дашборды, которые позволяют человеку-оператору быстро найти корневую причину сбоя. Но когда основным потребителем данных становится AI-агент (в роли самоконтроля или супервизора), ценность UI обнуляется.
Для агента не важен график задержек в Prometheus. Ему нужна Machine-Readable Telemetry — структурированные данные, по которым модель может рассуждать в реальном времени. Мы переходим от эпохи «мониторинга для людей» к эпохе «инфраструктуры для рассуждений». Это означает, что данные должны храниться и передаваться не в виде агрегированных метрик, а в виде детальных семантических трейсов, которые можно подать обратно в LLM в качестве контекста для принятия решения о корректировке курса.
2. Семантическая дивергенция и феномен Goal Drift
Главный враг автономных агентов — это не галлюцинация одного ответа, а Goal Drift (дрейф цели). Это процесс постепенного смещения фокуса внимания агента в ходе многошагового цикла. Под воздействием промежуточных данных LLM может переоценить значимость второстепенной детали и сделать её новым приоритетом, постепенно забывая об исходном запросе.
Рассмотрим техническую цепочку событий:
Исходная цель → Шаг 1 (Поиск) → Промежуточный результат (встречается интересная, но нерелевантная деталь) → Смещение внимания → Шаг 2 (Поиск по новой, ошибочной цели) → ... → Финальный бессмысленный ответ.
С точки зрения классического распределенного трейсинга (например, Jaeger или Zipkin), мы видим идеальную последовательность вызовов: запрос → ответ → следующий запрос. Но в реальности система вошла в состояние дивергенции — её вектор движения в пространстве задачи стал перпендикулярен целевому вектору.
Анализ решения: Чтобы купировать Goal Drift, недостаточно просто логировать действия. Необходима карта намерений (Intention Map). На каждом узле графа агент должен фиксировать не только результат, но и краткое семантическое обоснование (rationale): «Я вызываю инструмент X, чтобы уточнить параметр Y, который необходим для достижения цели Z». Только сравнивая эти обоснования между итерациями через косинусное сходство эмбеддингов, можно математически зафиксировать момент, когда агент «свернул не туда» еще до того, как он выдаст финальный ответ.
3. Переход к семантическому трейсингу (Semantic Tracing)
Для реального контроля над агентами необходимо переосмыслить понятие «спана». Классический спан фиксирует время и статус. Семантический спан должен фиксировать когнитивный след модели.
Предлагаемая схема семантического трейса (5 обязательных компонентов):
- Input State Snapshot: Снимок краткосрочной памяти и контекста перед началом действия. Это позволяет понять, на какой основе принималось решение и какие данные были доступны модели.
- Reasoning Chain: Скрытая цепочка рассуждений (Chain-of-Thought), которая привела к выбору конкретного инструмента. Здесь фиксируется внутренняя логика: «Если A, то B».
- Expected Outcome Vector: Описание того, какой результат агент ожидает получить от этого шага и как этот результат должен изменить его общее состояние (state transition).
- Actual Outcome & Delta: Что было получено на самом деле и насколько это отклонение влияет на дальнейший путь. Здесь фиксируется семантическая разница между ожиданием и реальностью.
- Confidence Score: Числовая оценка уверенности модели в том, что текущий шаг является оптимальным для достижения финальной цели.
Когда эти данные структурированы, мониторинг превращается в анализ данных. Например, если Confidence Score падает на протяжении трех итераций подряд при одновременном росте задержек, система может автоматически сигнализировать о вероятном зацикливании или тупике, даже если все HTTP-ответы возвращаются с кодом 200.
4. Closed-Loop Observability: Supervisor-Observer Pattern
Ключевой вывод: в агентных системах мониторинг не может быть внешней «пристройкой» для разработчика. Он должен быть интегрирован в runtime-цикл исполнения. Мы предлагаем архитектуру Supervisor-Observer.
В этой модели создается жесткое разделение обязанностей: Worker Agent (выполняет задачу) и Supervisor Agent (контролирует выполнение). Supervisor не имеет доступа к инструментам решения задачи, его единственная функция — анализ семантических трейсов Worker-а в реальном времени.
Механизмы оперативного управления Supervisor-а:
- Валидация сходимости (Convergence Check): Supervisor сравнивает семантический вектор состояния на шаге N и шаге N+1. Если расстояние между ними стремится к нулю (состояние почти не меняется), но цель не достигнута — зафиксирована Loop Hallucination.
- Принудительный Hard Reset: При обнаружении критической дивергенции Supervisor имеет право прервать выполнение, очистить стейк агента до последнего стабильного чекпоинта и вернуть его на этап планирования с явным указанием: «Ты ушел в сторону в этом месте, пересмотри стратегию».
- Динамический Circuit Breaker: Если агент проявляет признаки «паники» (быстрая смена инструментов без прогресса по Goal Drift), Supervisor временно блокирует определенные API-методы, заставляя модель сменить стратегию.
5. Инфраструктурный вызов: High-Cardinality и ClickHouse
Переход к семантическому трейсингу создает колоссальную нагрузку на хранение. Традиционные системы логирования (ELK) здесь буксуют, так как нам нужен моментальный поиск и агрегация по миллионам уникальных семантических векторов и трейсов. Мы имеем дело с данными сверхвысокой кардинальности (High-Cardinality).
Для таких задач обязательным становится использование OLAP-хранилищ, таких как ClickHouse. Только они позволяют в реальном времени выполнять аналитические запросы по миллионам трейсов, чтобы понять, в какой именно точке графа тысячи агентов начинают «дрейфовать» в сторону. Это превращает мониторинг из «смотрения в логи» в полноценный Data Science над поведением моделей.
6. Высшая точка: Telemetry as Context и Self-Healing Loop
Финальный этап развития — когда данные мониторинга становятся входным сигналом для самого агента. Вместо того чтобы ждать, пока Supervisor прервет выполнение, агент получает в контекст данные о своем Confidence Score и векторе сходимости.
Это создает Self-Healing Loop (петлю самовосстановления): агент видит, что его уверенность падает, а семантический прогресс к цели остановился. Он может самостоятельно инициировать перепланирование, используя данные из своего собственного трейса как доказательство ошибки. Таким образом, Observability перестает быть инструментом анализа сбоев и становится частью когнитивного цикла агента.
Пример: Технический OK vs Семантический Fail
Представим агента, который должен «найти лучшую цену на серверы Dell».
Технический трейс (Jaeger):
1. GET /search (200 OK, 200ms) → 2. GET /details (200 OK, 150ms) → 3. POST /final_answer (200 OK, 100ms).
Вердикт мониторинга: Система работает идеально.
Семантический трейс (Semantic Tracing):
Шаг 1: Поиск цен. (Confidence: 0.9)
Шаг 2: Агент находит статью «История компании Dell» и начинает изучать биографию Майкла Делла. (Confidence: 0.4, Vector Shift: высокий).
Шаг 3: Агент выдает ответ: «Майкл Делл основал компанию в 1984 году».
Вердикт семантического мониторинга: Критический провал (Goal Drift). Цель смещена с «цены» на «биографию».
Вердикт
Попытка запустить автономных агентов в промышленный продакшн с классическим мониторингом — это техническая неосмотрительность. Вы будете узнавать о сбоях не из дашбордов, а из гневных писем клиентов, получивших бессмысленные ответы. Для построения зрелых AI-сервисов необходимо внедрять семантический трейсинг, Supervisor-слои и переход на Machine-Readable Telemetry. В противном случае вы создаете не интеллектуальную систему, а непредсказуемый черный ящик с правами доступа к вашей инфраструктуре.
Источники
1. Observability was built for humans. AI agents need something different — Анализ сдвига к Machine-Readable Telemetry.
2. ClickHouse Documentation — Работа с данными высокой кардинальности в реальном времени.
3. Arize Phoenix: LLM Observability — Практика семантического трейсинга и визуализации графов рассуждений.
4. Liu et al. (2023), «Lost in the Middle: How Language Models Use Long Contexts» — Исследование деградации внимания в длинных контекстах (основа для анализа Goal Drift).
Продолжение темы
Еще статьи

OpenAI будет предоставлять США новые ИИ-модели на проверку
Компания выразила готовность пройти аудит актуальных и будущих версий систем на соответствие нормам безопасности и этики в рамках президентского указа.

Anthropic наладила диалог с властями США перед IPO
Компания, ранее признанная Пентагоном источником рисков для цепочек поставок из-за отказа интегрировать ИИ в военные задачи, перешла к конструктивному взаимодействию с пр...

СПбГУ и Сбербанк создадут лабораторию фундаментальных исследований ИИ
Соглашение предусматривает создание R&D-подразделения на базе самого молодого факультета вуза, где будут работать над основами ИИ следующего поколения.

AMD связала рост спроса на многоядерные процессоры с популярностью ИИ-агентов
Финансовый директор AMD Джин Ху на конференции Bank of America дала комментарии к квартальному отчёту и объяснила причины 20-процентного увеличения спроса на продукцию ко...